软件系统中上下游区分
前言
在我们日常工作当中,经常会听到这些词汇,与上游xx对接、升级要保证下游xx兼容性,据我了解啊,很多人还搞不起什么是上游、什么是下游,或者脑袋里很模糊,不会去判断这些。那么搞清楚这些概念,对于我们的软件设计还是很有必要的,为了搞清楚,那么下面我先举几个例子来介绍下:
例如:
我们的上游的xx系统今天down掉了,导致我们一部分业务没有闭环,需要晚些时候去补偿。
我们提供的接口被调用频率过高,爆掉了,导致下游的几个厂商业务阻断1小时。
在自然界中,上游和下游一般是指我们生活中的河流流向,如下图所示:

例如咱们的长江、黄河的上游到下游;
长江: 青藏高原的唐古拉山脉➡️➡️➡️ 东海
黄河: 青藏高原的巴颜喀拉山脉➡️➡️➡️渤海
今天去搜索了很多国内外的文章, 然而对于软件设计中的上游和下游,是有很大争议的,好多文章不好理解,都是名词解释名词,我总结下。
总结
总结出2个理论;
- 河流理论
- 终点理论
河流理论
判断上下游最好方法是想象一条河。
下游的水肯定是来自上游的。
如果有人破坏了河的下游部分,那将对上游没有影响。
如果有人破坏了河的上游部分,这将影响下游,即不会得到任何水。
因此,下游服务取决于上游服务。如果上游服务被删除,则下游服务将无法正常工作。
把软件设计中的数据流、依赖流类比河流去思考即可。
组件

组件C依赖于组件B,而组件B又依赖于组件A。
按照河流理论
去掉B,C无法工作,故B是C的上游。
去掉A,B无法工作,故A是B的上游。
服务
用户调用A服务,A服务调用B服务。
去掉B服务,A服务无法工作,故B是A的上游。
去掉A服务,User无法工作,故A是User的上游。
终点理论
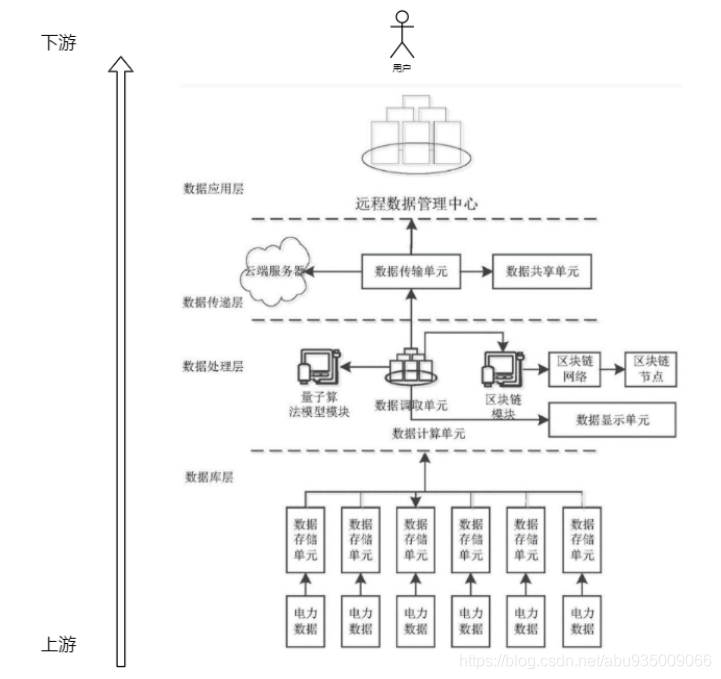
这里的终点,类似于长江的终点东海,黄河的终点渤海,对应于软件设计即面向于终端用户,越靠近用户的就是下游。
数据从起点数据库【上游】,经过数据处理层、数据传递层、数据应用层到终端【下游】用户。
总结收尾
一般情况下,我们把系统或者组件间的数据流、依赖流类比于河流,从数据流源头到终点,即河流的上游到下游。
其他场景,如果不太好判断的话,可以用终点理论,面向终点的就是下游,例如web系统中的越靠近用户的越是下游,数据处理分析系统中的越靠近处理结果报表的越是下游。
