五种实现延迟队列的方式
五种实现延迟队列的方式
定时任务轮询db
用户下单后db中会生成一条订单记录,记录了订单号、用户ID、创建时间、订单详情、订单状态等信息。假设超时时间是600秒,我们后台起一个定时任务,每隔固定时间运行一次,每次扫描db中的超时订单select * from order where createTime <= now()-600,然后取消查询到的订单。
这种方法实现简单,但是有很多缺点。超时时间通常是秒级的,如果定时任务每秒运行一次,那么就相当于每秒就要对订单表做一次扫描,这是相当消耗db资源的操作,因此定时任务一般不会设置为秒级;但是如果设置为分钟级,又会牺牲即时性,比如600秒超时,很有可能660秒的时候订单才被取消。
JDK 的DelayQueue
DelayQueue 是JDK中提供的延时队列,内部封装优先级队列,并且提供空阻塞功能。DelayQueue中所有元素必须实现Delayed接口getDelay方法,此方法返回剩余有效时间。
DelayQueue 类
public class DelayQueue<E extends Delayed> extends AbstractQueue<E>
implements BlockingQueue<E>
DelayQueue 继承AbstractQueue抽象类,实现BlockingQueue接口,元素必须实现实现Delayed接口。
Delayed 接口
public interface Delayed extends Comparable<Delayed>
Delayed 接口继承Comparable接口,所有子类都具有比较功能
Delayed 方法
// 返回剩余到期时间
long getDelay(TimeUnit unit);
DelayQueue 属性
// 锁对象
private final transient ReentrantLock lock = new ReentrantLock();
// 优先级队列
private final PriorityQueue<E> q = new PriorityQueue<E>();
// 头线程
private Thread leader = null;
// 条件
private final Condition available = lock.newCondition();
通过属性就能看出,他是通过优先级队列实现,快到期的排前面,每次取优先级队列头,看先是否到期。顺便说一下,优先级队列我们是当无界队列的,所以延时队列也可以称为无界队列。
**DelayQueue 出队 **
出队,为空返回null
public E poll() {
// 获取锁
final ReentrantLock lock = this.lock;
lock.lock();
try {
// 获取优先级队列头节点
E first = q.peek();
// 判断头节点是否为空,不为空判断剩余过期时间
if (first == null || first.getDelay(NANOSECONDS) > 0)
return null;
else
// 剩余过期时间小于0,优先级队列出队
return q.poll();
} finally {
// 解锁
lock.unlock();
}
}
出队,为空阻塞
public E take() throws InterruptedException {
// 获取锁
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
// 自旋
for (;;) {
// 获取优先级队列头节点
E first = q.peek();
// 优先级队列为空
if (first == null)
// 阻塞
available.await();
else {
// 判断头元素剩余时间是否小于等于0
long delay = first.getDelay(NANOSECONDS);
if (delay <= 0)
// 优先级队列出队
return q.poll();
// 到这,说明剩余时间大于0
// 头引用置空
first = null;
// leader线程是否为空,不为空就等待
if (leader != null)
available.await();
else {
// 设置leader线程为当前线程
Thread thisThread = Thread.currentThread();
leader = thisThread;
try {
// 休眠剩余秒
available.awaitNanos(delay);
} finally {
// 休眠结束,leader线程还是当前线程
// 置空leader
if (leader == thisThread)
leader = null;
}
}
}
}
} finally {
// leader线程为空,并且first不为空
// 唤醒阻塞的leader,让它再去试一次
if (leader == null && q.peek() != null)
available.signal();
// 解锁
lock.unlock();
}
}
出队,空时阻塞,超时退出
public E poll(long timeout, TimeUnit unit)
throws InterruptedException {
// 获取剩余时间
long nanos = unit.toNanos(timeout);
// 获取锁
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
// 自旋
for (;;) {
// 获取优先级队列头
E first = q.peek();
// 头为空
if (first == null) {
// 剩余时间小于等于0返回空
// 否则继续等待
if (nanos <= 0)
return null;
else
nanos = available.awaitNanos(nanos);
} else {
// 获取头剩余过期时间
long delay = first.getDelay(NANOSECONDS);
// 剩余时间小于等于0,优先级队列出队
if (delay <= 0)
return q.poll();
// 等待时间小于等于0,返回null
if (nanos <= 0)
return null;
// 到这,说明头元素过期时间大于0
// 头引用置空
first = null;
// leader不为空,等待时间短的
if (nanos < delay || leader != null)
nanos = available.awaitNanos(nanos);
else {
// 设置leader为当前线程
Thread thisThread = Thread.currentThread();
leader = thisThread;
try {
// 等待剩余时间
long timeLeft = available.awaitNanos(delay);
// 计算剩余超时间(防止恶意唤醒)
// (delay - timeLeft)计算等待了多长时间
nanos -= delay - timeLeft;
} finally {
// 休眠结束,leader线程还是当前线程
// 置空leader
if (leader == thisThread)
leader = null;
}
}
}
}
} finally {
// leader线程为空,并且first不为空
// 唤醒阻塞的leader,让它再去试一次
if (leader == null && q.peek() != null)
available.signal();
// 解锁
lock.unlock();
}
}
redis的zset实现延迟队列
zset是set的一个升级版本,他在set的基础上增加了一个顺序属性,这一属性在添加修改元素的时候可以指定,每次指定后,zset会自动重新按新的值调整顺序。 可以对指定键的值进行排序权重的设定,它应用排名模块比较多。
比如一个存储全班同学成绩的 Sorted Sets,其集合 value 可以是同学的学号,而 score 就可以是其考试得分,这样在数据插入集合的时候,就已经进行了天然的排序。另外还可以用 Sorted Sets 来做带权重的队列,比如普通消息的 score 为1,重要消息的 score 为2,然后工作线程可以选择按 score 的倒序来获取工作任务,让重要的任务优先执行。
zset集合可以完成有序执行、按照优先级执行的情况;
Redis实现延时任务,是通过其数据结构ZSET来实现的。
ZSET会储存一个score和一个value,可以将value按照score进行排序,而SET是无序的。
延时任务的实现分为以下几步来实现:
将任务的执行时间作为score,要执行的任务数据作为value,存放在zset中;
用一个进程定时查询zset的score分数最小的元素,可以用
ZRANGEBYSCORE key -inf +inf limit 0 1 withscores命令来实现;如果最小的score小于等于当前时间戳,就将该任务取出来执行,否则休眠一段时间后再查询
redis的ZSET是通过跳跃表来实现的,复杂度为O(logN),N是存放在ZSET中元素的个数。
用redis来实现可以依赖于redis自身的持久化来实现持久化,redis的集群来支持高并发和高可用。因此开发成本很小,可以做到很实时。
什么是跳表
在讲zset数据结构时,先学习下跳表数据结构。
我们知道二叉搜索算法能够高效的查询数据,但是需要一块连续的内存,而且增删改效率很低。
跳表,是基于链表实现的一种类似“二分”的算法。它可以快速的实现增,删,改,查操作。
我们先来看一下单向链表如何实现查找

当我们要在该单链表中查找某个数据的时候需要的时间复杂度为O(n). 即需要循环一层,挨个比较下。
怎么提高查询效率呢?如果我们给该单链表加一级索引,将会改善查询效率:
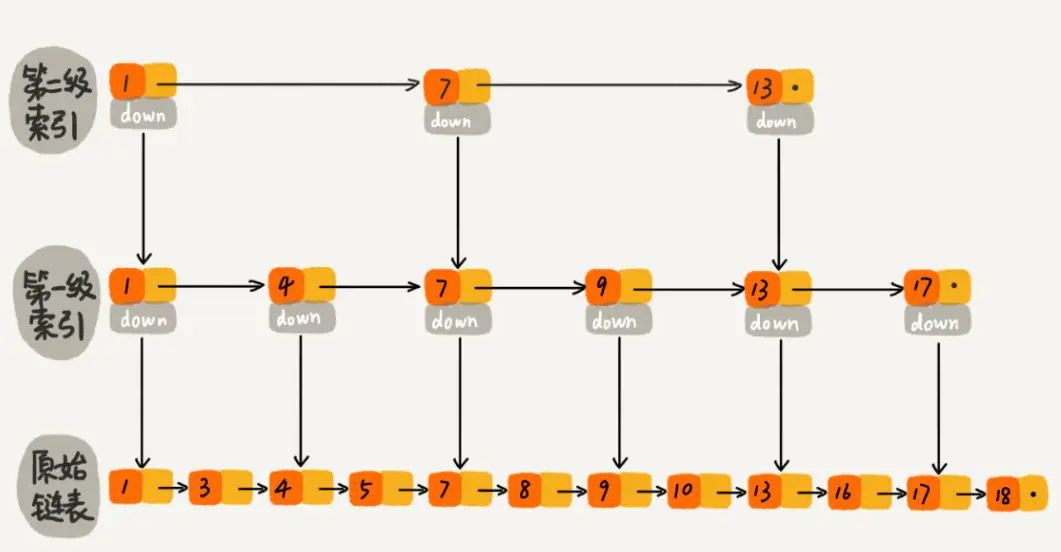
如图所示,当我们每隔一个节点就提取出来一个元素到上一层,把这一层称作索引,其中的down指针指向原始链表。
当我们查找元素16的时候,单链表需要比较10次,而加过索引的两级链表只需要比较7次。当数据量增大到一定程度的时候,效率将会有显著的提升。
如果我们再加多几级索引的话,效率将会进一步提升。这种链表加多级索引的结构,就叫做跳表。
实现跳表的java代码在demo项目中
zset数据结构的实现
zset 结构中,既支持按单个元素查询,又支持范围查询,是如何实现的呢?我们深入代码分析,在 Redis 的 t_zset.c 的注释中,提到:
/* ZSETs are ordered sets using two data structures to hold the same elements
* in order to get O(log(N)) INSERT and REMOVE operations into a sorted
* data structure.
*
* The elements are added to a hash table mapping Redis objects to scores.
* At the same time the elements are added to a skip list mapping scores
* to Redis objects (so objects are sorted by scores in this "view").
翻译过来是 Redis 中有两种数据结构来支持 zset 的功能,一个是 hash table ,一个是 skip list。先来看一下 zset 在代码中的定义:
typedef struct zset {
dict *dict;
zskiplist *zsl;
} zset;
dict 是一个hash table ,各种编程语言中都有实现。可以保证 O(1) 的时间复杂度,不做过多解释。我们继续看 zskiplist 的定义:
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;
int level;
} zskiplist;
zskiplist 是 Redis 对 skiplist 做了变种,skiplist 就是我们常说的跳表。
加强版跳表
Redis 中的对 skiplist 做了些改造:
- 增加了后驱指针(
*backward) - 同时记录value 和 score,且 score 可以重复
- 第一层维护了双向链表
zset 结构整个类图如下:
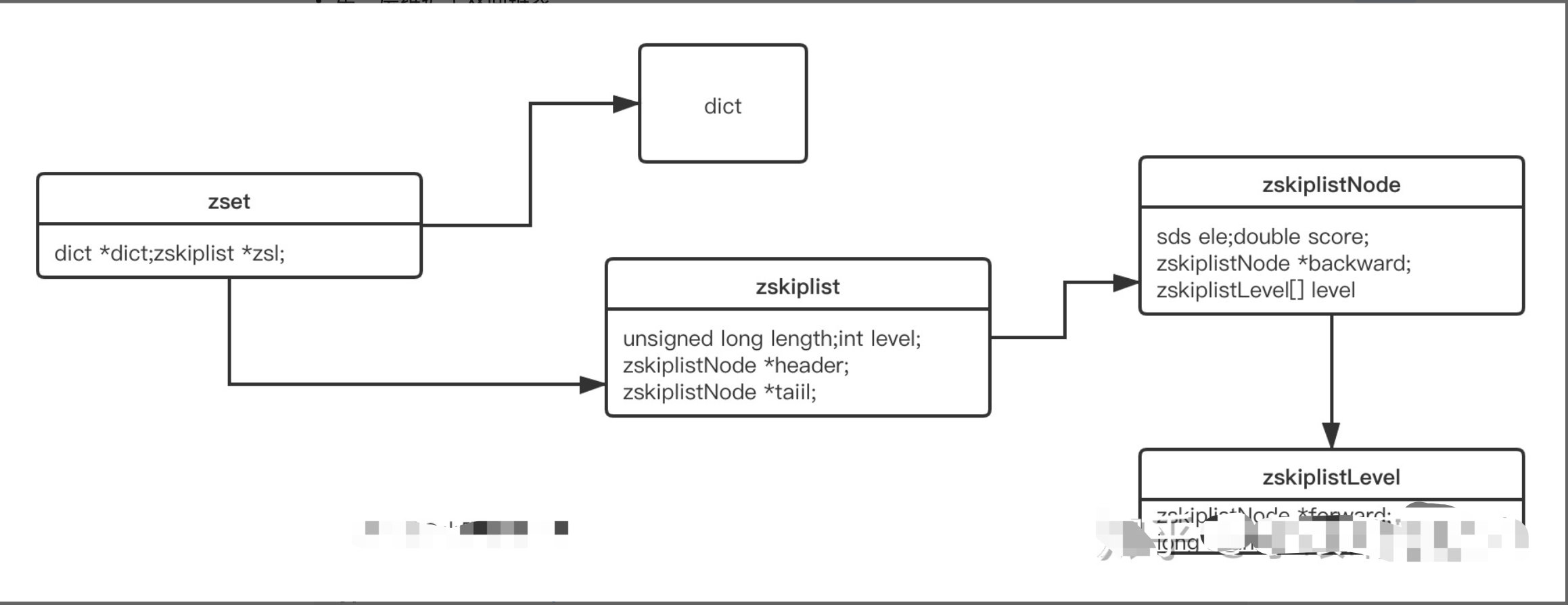
zskiplist 中保存的 zskiplistNode 节点定义:
typedef struct zskiplistNode {
sds ele;
double score;
struct zskiplistNode *backward; // 指向上一个节点
struct zskiplistLevel {
struct zskiplistNode *forward; // 指向下一个节点
unsigned long span; // 节点之前的跨度
} level[]; // 该节点的各层信息
} zskiplistNode;
zskiplistNode 中定义了 zskiplistLevel 的数组,用来保存该 node 在每一层的指针。
redis延迟队列使用场景
- 延时队列
zset 会按 score 进行排序,如果 score 代表想要执行时间的时间戳。在某个时间将它插入zset集合中,它变会按照时间戳大小进行排序,也就是对执行时间前后进行排序。
起一个死循环线程不断地进行取第一个key值,如果当前时间戳大于等于该key值的socre就将它取出来进行消费删除,可以达到延时执行的目的。
排行榜
经常浏览技术社区的话,应该对 “1小时最热门” 这类榜单不陌生。如何实现呢?如果记录在数据库中,不太容易对实时统计数据做区分。我们以当前小时的时间戳作为 zset 的 key,把贴子ID作为 member ,点击数评论数等作为 score,当 score 发生变化时更新 score。利用 ZREVRANGE 或者 ZRANGE 查到对应数量的记录。限流
滑动窗口是限流常见的一直策略。如果我们把一个用户的 ID 作为key 来定义一个 zset ,member 或者 score 都为访问时的时间戳。我们只需统计某个 key 下在指定时间戳区间内的个数,就能得到这个用户滑动窗口内访问频次,与最大通过次数比较,来决定是否允许通过。
java代码实现redis延迟队列
将任务加入队列中,作为生产者,TaskProducer.java:
@Component
public class TaskProducer {
@Autowired
private RedisTemplate<String,String> redisTemplate;
public void produce(Integer taskId, long exeTime) {
System.out.println("加入任务, taskId: " + taskId + ", exeTime: " + exeTime + ", 当前时间:" + System.currentTimeMillis());
redisTemplate.opsForZSet().add(RedisConst.DELAY_ZSET_KEY, String.valueOf(taskId),exeTime);
}
}
消费者,TaskConsumer.java:
@Component
public class TaskConsumer {
@Autowired
private StringRedisTemplate redisTemplate;
public void consumer() {
Executors.newSingleThreadExecutor().submit(new Runnable() {
@Override
public void run() {
while (true) {
//取最小的score(时间戳最小代表最早过期,则最先出列),并查询出score大于0小于等于当前时间的队列
Set<String> taskIdSet = redisTemplate.opsForZSet().rangeByScore(RedisConst.DELAY_ZSET_KEY, 0, System.currentTimeMillis(), 0, 1);
if (taskIdSet == null || taskIdSet.isEmpty()) {
System.out.println("没有任务");
} else {
taskIdSet.forEach(id -> {
long result = redisTemplate.opsForZSet().remove(RedisConst.DELAY_ZSET_KEY, id);
if (result == 1L) {
System.out.println("从延时队列中获取到任务,taskId:" + id + " , 当前时间:" + System.currentTimeMillis());
}
});
}
try {
TimeUnit.MILLISECONDS.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
});
}
}
消费者就是实现了延迟队列的算法:rangeByScore(RedisConst.DELAY_ZSET_KEY, 0, System.currentTimeMillis(), 0, 1)
满足了:
- 用一个进程定时查询zset的score分数最小的元素,可以用
ZRANGEBYSCORE key -inf +inf limit 0 1 withscores命令来实现;
- 如果最小的score小于等于当前时间戳,就将该任务取出来执行,否则休眠一段时间后再查询
写个单元测试模拟触发:
@RunWith(SpringRunner.class)
@SpringBootTest(classes = Demo1Application.class)
public class DelayQueenTests {
@Autowired
private TaskProducer taskProducer;
@Autowired
private TaskConsumer taskConsumer;
@Test
public void testDelayQueen_query(){
//创建 3个任务,并设置超时间为 10s 5s 20s
taskProducer.produce(1, System.currentTimeMillis() + 10000);
taskProducer.produce(2, System.currentTimeMillis() + 5000);
taskProducer.produce(3, System.currentTimeMillis() + 20000);
System.out.println("等待任务执行===========");
//消费端从redis中消费任务
taskConsumer.consumer();
try {
TimeUnit.MILLISECONDS.sleep(50000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
RabbitMQ的TTL+DLX
RabbitMQ可设置消息过期时间(TTL),当消息过期后可以将该消息投递到队列上设置的死信交换器(DLX)上。然后投递到死信队列中,重新消费。
- 什么是死信队列
死信交换机: DLX,dead-letter-exchange 其实就是在一般的队列上面设置dlx属性。 利用 dlx,当消息在一个队列中变成死信 (dead message) 之后,它能被重新 publish 到另一个 exchange,这个 exchange 就是 dlx, 而连接dead-letter-exchange交换机的队列就叫死信队列。
- 什么情况会变成死信队列
消息变成死信的原因有:
1.消息被拒绝 (basic.reject / basic.nack) 并且 reQueue=false
2.消息 TTL 过期
3.队列达到最大长度了
- 实现死信的两种方式
设置原生队列TTL参数
安装rabbitMQ官方提供的插件(rabbitmq-delayed-message-exchange),可支持对message设置TTL
- 写一个死信队列的场景,来实现请求第三方平台接口失败时,延时重试 厂里需要能够支持10万+的请求,要求有重试机制,时间两天,请记住2020年6月25号,这个端午假期,说是有三倍工资,拭目以待。(已验证确实发放三倍)
基本已经定了使用rabbitMQ实现负载分发,但是我们需要调用第三方平台的接口,而第三分平台接口貌似只支持每秒钟100次调用,超过这个频率了就会失败,或者报错。
**要求: **
- 消费者在调用第三方平台接口如果报错或者失败的情况下,要将失败的消息存起来
- 5秒后重试,同一消息重试不能超过3次。
- 多消费者不能重复消费
以下是基本的流程:
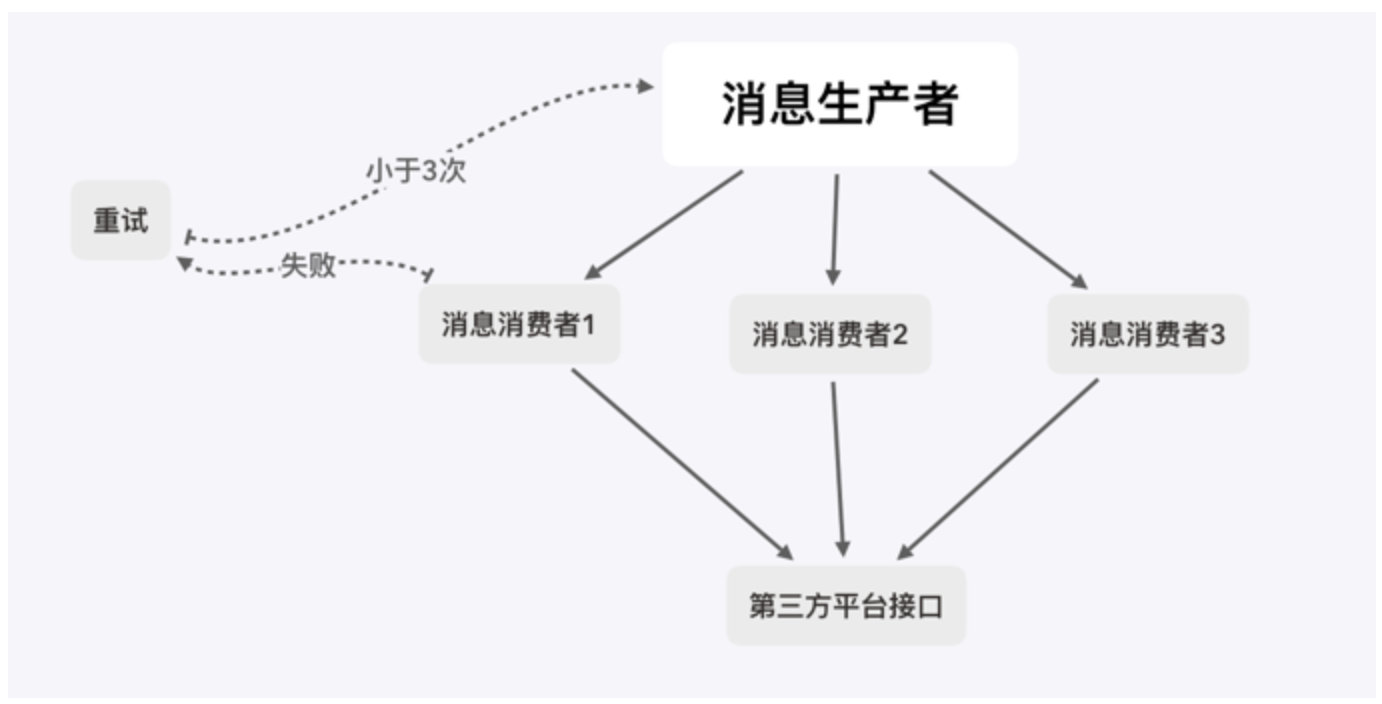
- MQ的交换机与队列配置如下:
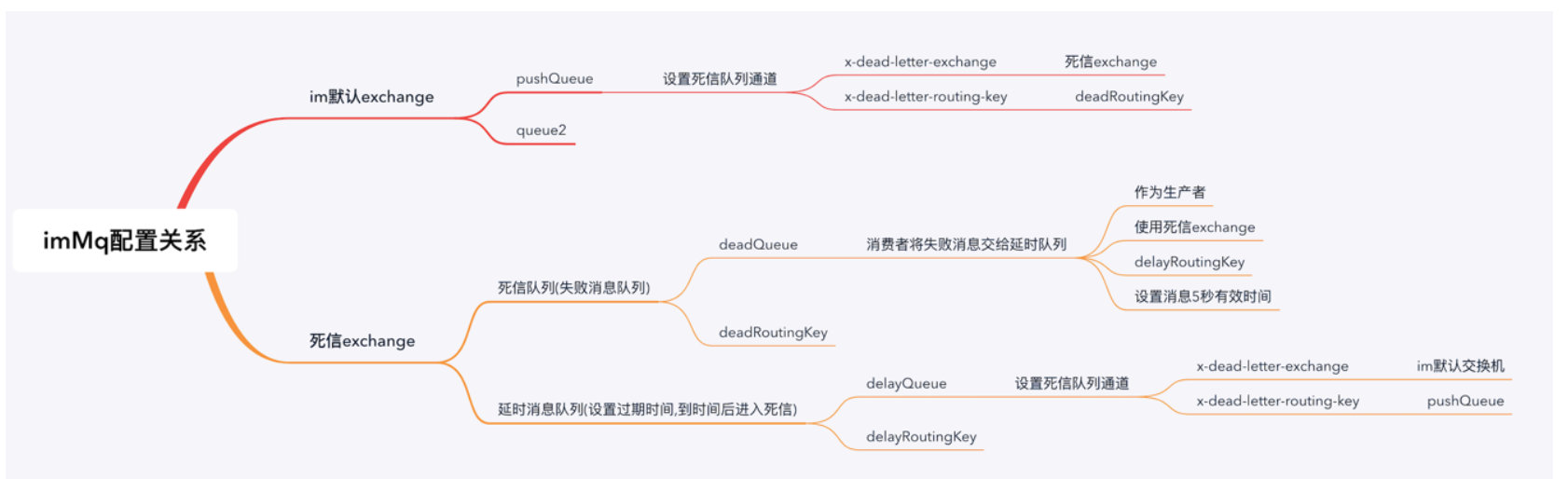
- IM在MQ的这个配置中的请求流程

时间片轮询
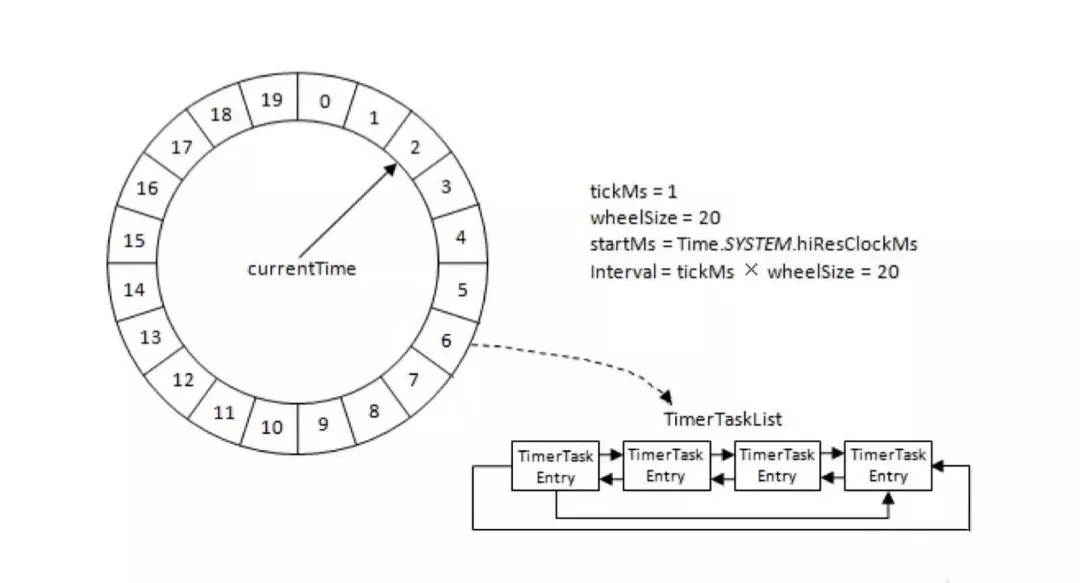
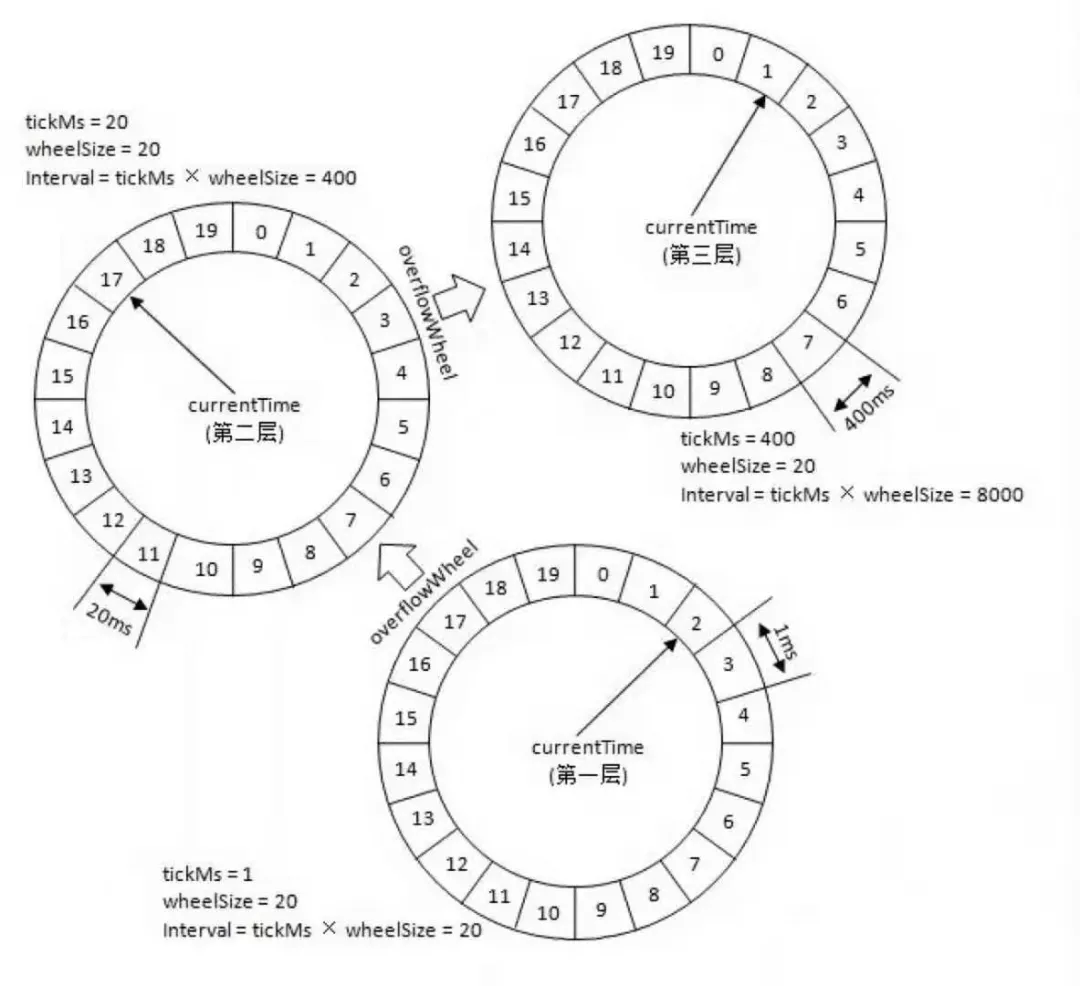
时间轮是通过代码实现的消费者的实现,并利用kafka的暂停和恢复功能来实现延时消费,不适用跨度比较长的延时消息,无法持久轮询状态,且执行时间误差较大,在实际的生产应用中很少使用。
延时消息队列最优的中间件实现是rocketMQ, rocketMQ显示的支持设置40天以内的任何时刻(单位为毫秒),并且支持延时消息持久化, 容灾能力强。
/*发送延时消息,需要设置延时时间,单位毫秒(ms),消息将在指定延时时间后投递,例如消息将在3秒后投递。*/
long delayTime = System.currentTimeMillis() + 3000;
msg.putUserProperty("__STARTDELIVERTIME", String.valueOf(delayTime));
/**
*若需要发送定时消息,则需要设置定时时间,消息将在指定时间进行投递,例如消息将在2021-08-10 18:45:00投递。
*定时时间格式为:yyyy-MM-dd HH:mm:ss,若设置的时间戳在当前时间之前,则消息将被立即投递给Consumer。
* long timeStamp = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").parse("2021-08-10 18:45:00").getTime();
* msg.putUserProperty("__STARTDELIVERTIME", String.valueOf(timeStamp));
*/
总结
| 方案 | 优点 | 缺点 |
|---|---|---|
| 定时任务轮询db | 实现简单,无技术难点、异常恢复、集群、分布式 | 影响数据库性能、时效性差 |
| JDK DelayQueue | 实现简单、性能较好 | 数据无法异常恢复、分布式/集群 |
| redis zset | 解藕、异常恢复、扩展性强、支持分布式、集群环境 | 增加redis维护、占用带宽、增加redis压力 |
| RabbitMQ的TTL+DLX | 更专业、解藕、异常恢复、扩展性强、支持分布式、集群环境 | 增加RabbitMQ维护、占用带宽 |
| kafka时间片轮询 | 性能好,效率高、速度快(内存中),支持集群环境 | 不适用时间跨度非常大的场景,不支持持久化与高可用 |
