2022年2月interView
- 1. 2022年2月interView
- 1.1. jvm的两种回收机制,cms和g1的工作原理及区别
- 1.2. JVM运行中新生代对象在什么情况下,会被上升到老年代?
- 1.3. JVM是如何与cpu、内存进行调度交互的?
- 1.4. 有个秒杀接口,接口中间调用了几个微服务接口,原来支持1000个QPS, 现在要求优化,将QPS提升到1万+,怎么优化?
- 1.5. 工作中有解决过什么问题,解决思路是什么?
- 1.6. 配置中心技术选型,各配置中心的区别与优缺点,为什么最终选择了那个?
- 1.7. 有两个List,每个list都有100w条数据,现在要将两个list中的重复数据取出来,有什么办法(也可以借助第三方中间件实现)?
- 1.8. rabbiMQ 配置问题
- 1.9. rabbitMQ 怎么保证100%消息不丢失?
- 1.10. 你们微服务系统主要使用了哪些监控系统
- 1.11. springcloud 限流设置具体是怎么设置的
- 1.12. java如何实现hash表的
- 1.13.
- 1.14. 单链表有什么优缺点
- 1.15. 在过去的项目中,是否有通过状态机去实现一些功能
- 1.16. 微服务的项目里是用什么方式实现限流和熔断降级的?
- 1.17. 如何实现接口的幂等性
- 1.18. mysql数据库有几种存储引擎
- 1.19. mysql数据库水平方向的扩展
- 1.20. 数据库什么时候分区,什么时候分库,什么时候分表
- 1.21. mysql数据库插入一条数据,具体做了什么事情
- 1.22. mysql的ACID是怎么实现的
- 1.23. mysql集群部署方式
- 1.24. 如何防止redis雪崩,穿透,击穿
- 1.25. redis有几种存储方式
- 1.26. linux系统零拷贝
- 1.27. 两个不同的网站,如何实现登陆状态同步
- 1.28. java8函数式编程用过哪些,举例说明
- 1.29. 对称加密与非对称加密
2022年2月interView
做总结,复习,学习。。。。。。
java所有问题基于jdk1.8
jvm的两种回收机制,cms和g1的工作原理及区别
cms
暂停性内存回收,采用标记–清除算法, 块状清理,容易产生更多碎片。
gc运行时将使所有线程挂起,导致系统服务出现短暂停止。
g1
jdk1.7推出,采用并行、并发标记整理算法,可预测停顿,产生更少的碎片, 以网格方式进行gc分析处理。
JVM运行中新生代对象在什么情况下,会被上升到老年代?
答:未被使用的时候,如果没有引用了,对象会被直接回收,引发ygc。
怎么判断对象可回收
需要进行一系列的可达性分析:
查找无GC Root引用后,jvm将对其作一次mark
jvm不期对已标记对象进行筛选,根据情况再决定是否调用finalize方法
如果对象被判定需要执行finalize方法,则将此对象移入F-Queue队列中,等待 Finalizer 线程执行
执行finalize方法中,GC将对F-Queue中对象进行二次标记,用来判定是否触发gc
通过一系列的 ‘GC Roots’ 的对象作为起始点,从这些节点出发所走过的路径称为引用链。当一个对象到 GC Roots 没有任何引用链相连的时候说明对象可回收,没有被使用。
可作为 GC Roots 的对象:
- 虚拟机栈(栈帧中的本地变量表)中引用的对象
- 方法区中类静态属性引用的对象
- 方法区中常量引用的对象
- 本地方法栈中 JNI(即一般说的 Native 方法) 引用的对象
堆中有对象可回收时,触发的哪种机制回收
gc时采用的算法
- 标记–清除算法
- 标记- 整理算法
老年代gc时采用的算法
- 复制算法
JVM是如何与cpu、内存进行调度交互的?
jvm相关文章参考:
https://blog.csdn.net/qq_41701956/article/details/81664921
https://www.cnblogs.com/yichunguo/p/12007038.html
https://blog.csdn.net/smartbetter/article/details/80561284
https://developer.aliyun.com/article/368436
有个秒杀接口,接口中间调用了几个微服务接口,原来支持1000个QPS, 现在要求优化,将QPS提升到1万+,怎么优化?
异步队列?
生产者消费者?
确保最终一致性?事后补偿机制
工作中有解决过什么问题,解决思路是什么?
应用重启问题
影响因素:
内存分配不合理,堆内存溢出导致crash
线程池使用不当,核心线程数设置太高,导致大量线程请求连接堵塞,占用内存与io, 最大线程数2n+3
问题分析:
以每秒打印一次gc情况:
jstat -gcutil 12 1000
发现ygc特别频繁,平均2分钟一次,一小时几乎30次,一天720次,而fullgc一天平均16次。
- 由于fullgc的效率远没有ygc高,所以肯定是因为内存分配不合理,导致fullgc频繁,而ygc的次数特别高,说明在年轻代的对象生产特别快,导致年轻代需要通过频繁的gc来释放更多的空间以便容纳新对象。而老年代gc频繁,说明有越来越多的长期未释放的对象或线程占用资源,需要移动到老年代,而老年代由于空间不足,只能通过不断gc来释放,但由于fullgc太过频繁,而由于又是使用的CMS作为收集方式,系统将暂停,所有线程将会被挂起,而随着时间推移,系统暂停时间越来越长,导致k8s健康检查失败,从而导致触发重启。
- 通过观察,应用中活动线程数超过了3000个,而默认一个线程栈大小是1M,如果这3000个线程一直不回收,或者nio发生堵塞,则就会OOM, 而出现这种情况的原因是线程池参数配置有问题(
N = int availableProcessors = Runtime.getRuntime().availableProcessors();docker容器不能使用这种写法, 取到的是宿主机的cpu线程数)
解决方案:
容器内存8G
- 调整jvm堆内存大小,将堆内存设置为5G(NewSize设置为3G,剩下的就是OldSize为2G), 还剩3G给非堆动态扩展(元空间默认大小21M, 其余将近3G内存由非堆支配)
- 设置线程池参数,将核心线程数设置为2+1,最大活跃线程数控制在2*2+1,blockQueue管道大小设置为100(经验参数),将系统线程数控制在105个左右,减少非堆的内存压力。
- 将jvm参数中的线程栈大小设置为512kb, 减少线程stack内存占用,提高线程池容量。
包冲突导致应用访问异常问题
现象:
- 应用可以正常启动
- 业务接口通过postman可正常返回
- curl 命令访问接口返回的http状态码为500,但有返回值
原因:
项目里有大量包冲突,其中hibenate的Validator包影响了springboot web中相关的包。
解决方式:
- 解决包冲突
- 删除hibernate相关包(用不到)
配置中心技术选型,各配置中心的区别与优缺点,为什么最终选择了那个?
nacos
apollo
discover server
有两个List,每个list都有100w条数据,现在要将两个list中的重复数据取出来,有什么办法(也可以借助第三方中间件实现)?
一个map,将重复数据取出
- 将list以k,v存入map
- 将第二个list遍历,将值作为key去取,取到值则将其放入到新list中
rabbiMQ 配置问题
服务端配置
num_acceptors.tcp tcp 接受TCP侦听器连接的Erlang进程数。
一旦打开了一个使用tcp连接的套接字,它就始终保持打开状态,直至任何一方关闭它或因为一个错误而终止。在建立一个连接时,一般为每一次请求产生一个新进程,num_acceptors就是控制产生新进程的个数。假设有一个监听进程,其任务是等待传入的tcp请求。只要一个请求到达,响应该连接请求的进程就变成了接收进程。默认的配置为num_acceptors.tcp = 10。
num_acceptors.tcp = 10
handshake_timeout
Maximum time for AMQP 0-9-1 handshake (after socket connection and TLS handshake), in milliseconds.
AMQP 0-9-1握手(socket连接和TLS握手之后)的最大时间,以毫秒为单位。
默认的配置为handshake_timeout = 10000。
handshake_timeout = 10000
channel_max
Maximum permissible number of channels to negotiate with clients, not including a special channel number 0 used in the protocol. Setting to 0 means “unlimited”, a dangerous value since applications sometimes have channel leaks. Using more channels increases memory footprint of the broker.
设置每个连接的最大允许通道数量。 0表示“没有限制”。默认的配置为channel_max = 2047。
channel_max = 2047
max_message_size
The largest allowed message payload size in bytes. Messages of larger size will be rejected with a suitable channel exception
最大消息大小设置,超过了会抛出相应的通道异常来拒绝消息。
默认值:134217728 byte, 最大值: 536870912 byte
集群相关配置
cluster_partition_handling
cluster_partition_handling
How to handle network partitions?
network partitions 就是脑裂,网络分裂,也叫 脑裂(split-brain)
如何处理rabbitMQ集群脑裂问题
一种在系统的任何两个集群之间的所有网络连接同时发生故障后所出现的情况。发生这种情况时,分裂的系统双方都会从对方一侧重新启动应用程序,进而导致重复服务或裂脑。由网络分裂造成的最为严重的问题是它会影响共享磁盘上的数据。默认为ignore模式。如何处理网络分裂?详细的文档可以参考官网文档
rabbitMQ提供了四种处理模式可选:
ignore:忽略不处理
pause_minority:暂停少数模式。
RabbitMQ在看到其他节点停止后自动处于少数(即少于或等于节点总数的一半)的群集节点。 因此,它从CAP定理中选择对可用性的分裂容差。 这确保了在网络分裂的情况下,单个分裂中的节点最多的将继续运行。 只要分裂开始,少数的节点就会暂停,并在分裂结束时再次启动。
autoheal:自动裁决。
如果分裂被认为已经发生,RabbitMQ将自动决定获胜分裂,并且将重新启动不在获胜分裂中的所有节点。 与pause_minority模式不同,它在分裂结束时生效,而不是在启动时生效。
pause_if_all_down:暂停全部关闭模式。
所有列出的节点都必须关闭以便RabbitMQ暂停群集节点。这接近暂停少数模式,但是,它允许管理员决定选择哪个节点,而不是依赖于上下文。例如,如果集群由机架A中的两个节点和机架B中的两个节点组成,并且机架之间的链路丢失,则暂停少数模式将暂停所有节点。如果管理员在机架A中列出了两个节点,那么在全部停机模式下,只有机架B中的节点才会暂停。请注意,列出的节点可能会在分区的两侧分裂:在这种情况下,没有节点会暂停。这就是为什么有一个额外的ignore / autoheal参数来指示如何从分区中恢复。
mirroring_sync_batch_size
在消息中镜像同步批量大小。增加这将加快同步,但批量总大小(以字节为单位)不得超过2 GiB。该设置可用于RabbitMQ 3.6.0或更高版本。默认的配置为 mirroring_sync_batch_size = 4096(4k)。
default:
mirroring_sync_batch_size = 4096
rabbitMQ集群发现机制
- Config file
- DNS
https://www.cnblogs.com/guchunchao/p/13176206.html#_label0
客户端配置
prefetchCount参数的作用
预加载,消费者消费之前将待消费消息放到本地block队列中,消费者消费完后直接从block中取下一消息f进行消费。
有哪些size配置,分别是做什么的
setTxSize:设置事务当中可以处理的消息数量。
rabbitMQ 怎么保证100%消息不丢失?
- HA
- 集群(镜像模式)
- 异地多活(federation插件)
你们微服务系统主要使用了哪些监控系统
链路追踪
skywalking
优点:
- 代码无侵入
- 有dashboard
- apache 开源
Spring Cloud Sleuth + zipkin
查看微服务调用关系,非常清晰
- twitter 开源
- 代码侵入
- 链路更清晰
、
性能监控&报警
Prometheus+Grafana
日志服务
elk
链路
springcloud 限流设置具体是怎么设置的
至少说出类名
实现 HystrixCommand父类
https://api.cloud.yisu.com/zixun/88871.html
https://blog.csdn.net/varyall/article/details/99722594
java如何实现hash表的
hashTable
单链表有什么优缺点
优:查找指点节点速度快,插入与删除不需要移动下标,所以插入删除也快
缺:
- 链表需要占用更多的内存,因为链表中的每个节点都包含一个指针引用,会一直占用内存
- 在链表中很难遍历元素或节点。 我们不能像按索引在数组中那样随机访问任何元素,如果我们要访问位置n处的节点,则必须遍历它之前的所有节点。 因此,访问节点所需的时间很大
https://blog.csdn.net/culing2941/article/details/108649963
在过去的项目中,是否有通过状态机去实现一些功能
熔断机制
规则引擎
微服务的项目里是用什么方式实现限流和熔断降级的?
为什么要限流
突发大并发量请求流入进来,可能将导致系统崩溃,无法响应。
限流的目的就是形成一种保护机制,让系统的入口流量和系统的负载达到一个平衡,保证系统在能力范围之内处理最多的请求。
有几种限流方式
按请求IP限流
springcloud gateway + RedisRateLimter实现
网关引入的redis-reactive,背压模式的redis:
<!--基于 reactive stream 的redis -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis-reactive</artifactId>
</dependency>
配置gateway针对某一服务的限流配置文件:
spring:
cloud:
gateway:
routes:
- id: requestratelimiter_route
uri: lb://upms
order: 10000
predicates:
- Path=/admin/**
filters:
- name: RequestRateLimiter
args:
redis-rate-limiter.replenishRate: 1 # 令牌桶的容积
redis-rate-limiter.burstCapacity: 3 # 流速 每秒
key-resolver: "#{@remoteAddrKeyResolver}" #SPEL表达式去的对应的bean
- StripPrefix=1
ps: 配置的RequestRateLimiter过滤器指的就是RequestRateLimiterGatewayFilterFactory.java
配置bean,多维度限流量的入口 对应上边key-resolver
/**
* 自定义限流标志的key,多个维度可以从这里入手
* exchange对象中获取服务ID、请求信息,用户信息等
*/
@Bean
KeyResolver remoteAddrKeyResolver() {
return exchange -> Mono.just(exchange.getRequest().getRemoteAddress().getHostName());
}
Spring Cloud Gateway 默认实现 Redis限流,如果扩展只需要实现ratelimter接口即可。
按请求地址限流
同ip限流类似
限流算法
令牌桶算法
固定窗口算法
滑动窗口算法
漏桶算法
有哪些实现框架
springcloud-zuul
https://www.cnblogs.com/smallfa/p/13929833.html
Hystixy
https://github.com/Netflix/Hystrix/wiki/How-To-Use#Synchronous-Execution
Sentinel
sentinel的限流规则是如何持久化的?
为什么要降级
微服务专家提出通过断路器模式来实现降级的规则。
降级的原理
哪些框架实现了降级
Hystixy
Sentinel
https://api.cloud.yisu.com/zixun/625804.html
如何实现接口的幂等性
数据库乐观锁
添加版本号或者时间戳
全局唯一键ID约束
由数据库的唯一键约束来保证无重复数据产生
唯一ID需保证分布式环境中全局唯一
客户端—->请求分布式ID—->携带分布式ID请求业务接口—>入库
如果有重复请求进来,则数据库唯一键约束会将此脏数据挡在外面。
防重Token令牌
请求业务接口前从服务端拿一个token(此token唯一,存在redis中, key=token,value=userId)—–>携带token访问新增接口—->服务端将token从redis中取出来,如果有值,且value与当前userId相匹配,则从redis中删除此token,并放行请求,否则就表示请求为重复请求或者非法请求。
传递请求ID+认证key
所谓请求ID,其实就是每次向服务端请求时候附带一个短时间内唯一不重复的序列号,该序列号可以是一个有序 ID,也可以是一个订单号,一般由下游生成,在调用上游服务端接口时附加该序列号和用于认证的 ID。
当上游服务器收到请求信息后拿取该 请求ID 和下游 认证ID 进行组合,形成用于操作 Redis 的 Key,然后到 Redis 中查询是否存在对应的 Key 的键值对,根据其结果:
- 如果存在,就说明已经对该下游的该序列号的请求进行了业务处理,这时可以直接响应重复请求的错误信息。
- 如果不存在,就以该
Key作为 Redis 的键,以下游关键信息作为存储的值(例如下游商传递的一些业务逻辑信息),将该键值对存储到 Redis 中 ,然后再正常执行对应的业务逻辑即可。
mysql数据库有几种存储引擎
innerDB
- 支持事务处理、ACID事务特性
- 实现了SQL标准的四种隔离级别
- 支持行级锁和外键约束
- 可以利用事务日志进行数据恢复
- 不支持FullText类型的索引,没有保存数据库行数,计算count(*)需要全局扫描
- 支持自动增加列属性auto_increment
MyiSam
- Mysql的默认引擎,其目标是快速读取。
- 快速读取,如果频繁插入和更新的话,因为涉及到数据全表锁,效率并不高
- 保存了数据库行数,执行count时,不需要扫描全表;
- 不支持数据库事务;
- 不支持行级锁和外键;
- 不支持故障恢复
- 支持全文检索FullText,压缩索引。
其它引擎未使用过
mysql数据库水平方向的扩展
Mysql的扩展方案包括Scale Out和Scale Up两种。
Scale Out(横向扩展)是指Application可以在水平方向上扩展。一般对数据中心的应用而言,Scale out指的是当添加更多的机器时,应用仍然可以很好的利用这些机器的资源来提升自己的效率从而达到很好的扩展性。
Scale Up(纵向扩展)是指Application可以在垂直方向上扩展。一般对单台机器而言,Scale Up值得是当某个计算节点(机器)添加更多的CPU Cores,存储设备,使用更大的内存时,应用可以很充分的利用这些资源来提升自己的效率从而达到很好的扩展性。
MySql的Sharding策略包括垂直切分和水平切分两种。
垂直(纵向)拆分:
是指按功能模块拆分,以解决表与表之间的io竞争。比如分为订单库、商品库、用户库…这种方式多个数据库之间的表结构不同。
表结构设计垂直切分。常见的一些场景包括
a).大字段的垂直切分。单独将大字段建在另外的表中,提高基础表的访问性能,原则上在性能关键的应用中应当避免数据库的大字段
b). 按照使用用途垂直切分。例如企业物料属性,可以按照基本属性、销售属性、采购属性、生产制造属性、财务会计属性等用途垂直切分
c). 按照访问频率垂直切分。例如电子商务、Web 2.0系统中,如果用户属性设置非常多,可以将基本、使用频繁的属性和不常用的属性垂直切分开
水平(横向)拆分:
将同一个表的数据进行分块保存到不同的数据库中,来解决单表中数据量增长出现的压力。这些数据库中的表结构完全相同。
数据库什么时候分区,什么时候分库,什么时候分表
分区
分区只不过把存放数据的文件分成了许多小块,分区后的表还是一张表,数据处理还是由自己来完成。
分区突破了磁盘I/O瓶颈,想提高磁盘的读写能力,来增加mysql性能。
分区实现是比较简单的,建立分区表,跟建平常的表没什么区别,并且对代码端来说是透明的。
sharding(分片)
分片是把数据库横向扩展(Scale Out)到多个物理节点上的一种有效的方式,其主要目的是为突破单节点数据库服务器的 I/O 能力限制,解决数据库扩展性问题。Shard这个词的意思是“碎片”。如果将一个数据库当作一块大玻璃,将这块玻璃打碎,那么每一小块都称为数据库的碎片(DatabaseShard)。将整个数据库打碎的过程就叫做分片,可以翻译为分片。
形式上,分片可以简单定义为将大数据库分布到多个物理节点上的一个分区方案。
每一个分区包含数据库的某一部分,称为一个片,分区方式可以是任意的,并不局限于传统的水平分区和垂直分区。一个分片可以包含多个表的内容甚至可以包含多个数据库实例中的内容。每个分片被放置在一个数据库服务器上。一个数据库服务器可以处理一个或多个分片的数据。系统中需要有服务器进行查询路由转发,负责将查询转发到包含该查询所访问数据的分片或分片集合节点上去执行。
分库
把一个库拆成多个库,突破库级别的数据库操作I/O瓶颈。
原因:
- 单库数据量太大
瓶颈:单个数据库处理能力有限,单库所在服务器上磁盘空间不足,I/O有限;
解决方法:切分成更多更小的库
分表
分表从表面意思说就是把一张表分成多个小表,分区则是把一张表的数据分成N多个区块,这些区块可以在同一个磁盘上,也可以在不同的磁盘上。
https://zhuanlan.zhihu.com/p/136963357
mysql数据库插入一条数据,具体做了什么事情
mysql数据库组成:
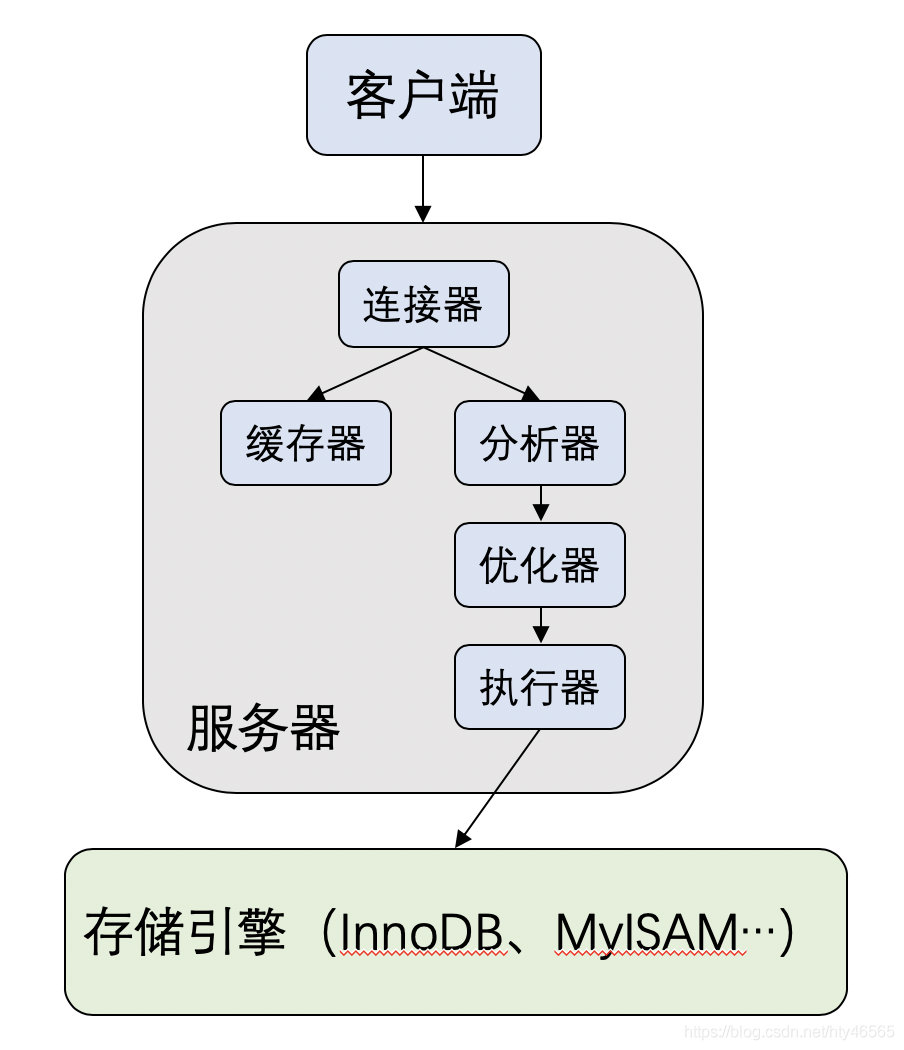
https://zhuanlan.zhihu.com/p/354255965
mysql的ACID是怎么实现的
事务具有 ACID 四个特性——原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)。
先来简单回顾一下 ACID 的定义:
原子性(A):事务作为一个整体被执行,包含在其中的对数据库的操作要么全部被执行,要么都不执行。
一致性(C):事务开始前和事务结束后,数据库的完整性没有被破坏。即写入的数据必须完全符合所有的预设约束、触发器、级联回滚等。
隔离性(I):多个事务并发执行时,一个事务的执行不应影响其他事务的执行。
持久性(D):已被提交的事务对数据库的修改应该永久保存在数据库中。即使系统挂了,数据也不会丢。
从数据库层面,数据库通过原子性、隔离性、持久性来保证一致性。也就是说ACID四大特性之中,C(一致性)是目的,A(原子性)、I(隔离性)、D(持久性)是手段,是为了保证一致性,数据库提供的手段。数据库必须要实现AID三大特性,才有可能实现一致性。例如,原子性无法保证,显然一致性也无法保证。
原子性
Mysql怎么保证原子性的?
是利用Innodb的undo log。
undo log名为回滚日志,是实现原子性的关键,当事务回滚时能够撤销所有已经成功执行的sql语句,他需要记录你要回滚的相应日志信息。
例如
(1)当你delete一条数据的时候,就需要记录这条数据的信息,回滚的时候,insert这条旧数据
(2)当你update一条数据的时候,就需要记录之前的旧值,回滚的时候,根据旧值执行update操作
(3)当年insert一条数据的时候,就需要这条记录的主键,回滚的时候,根据主键执行delete操
undo log记录了这些回滚需要的信息,当事务执行失败或调用了rollback,导致事务需要回滚,便可以利用undo log中的信息将数据回滚到修改之前的样子。
一致性
由其它三个特性保证数据的一致性
隔离性
Mysql提供了四种隔离级别,其中
Repeatable read是默认的隔离级别
select @@tx_isolation;
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 未提交读(Read uncommitted) | 允许 | 允许 | 不允许 |
| 已提交读(Read committed) | 不允许 | 允许 | 允许 |
| 可重复读(Repeatable read) | 不允许 | 不允许 | 允许 |
| 可串行化(Serializable) | 不允许 | 不允许 | 不允许 |
脏读
| 会话 1 | 会话2 |
|---|---|
| begin | begin |
| update table set age=12 where id=1 | |
| select age from table where id=1 | |
| commit | commit |
读取到会话2中未提交的数据,就是脏读,只有隔离级别是未提交读时,才会出现。
不可重复读
针对update重复查询两次,得到不一样的结果
| 会话1 | 会话2 |
|---|---|
| begin | begin |
| select age from table where id=1 | |
| update age=10 where id=1 | |
| commit | |
| select age from table where id=1 | |
| commit |
意思在一个事务中,重复的查询两次,第二次读到了会话2事务中已提交更改数据,从而得到的结果不一致,就叫不可重复读(一致的数据)。
幻读
针对插入
| 会话1 | 会话2 |
|---|---|
| begin | begin |
| select * from table where id>2 | |
| insert into table(id,age) values(5,10); | |
| commit | |
| select * from table where id>2 | |
| commit |
在一个事务中,同样的查询条件查询两次,得到的数据记录条数不一致,能查到其它事务已提交的插入的数据记录。
数据库隔离级别从低到高排序:未提交读—>已提交读—->可重复读—->可串行化
隔离级别越高,越能保证数据的完整性和一致性,但是对并发性能的影响也越大。
持久性
Mysql怎么保证持久性的?
还是Innodb的undo log。
我们知道程序修改数据的时候,是先将数据从磁盘加载到内存,然后修改完再由内存写回磁盘。持久化其实就是将内存里的数据写入磁盘。因此,持久性的关键就在于如何保证数据可以由内存顺利写入磁盘。
我们有以下几个方案:
方案一:
加载数据到内存
修改内存
然后写回磁盘
提交事务
方案二:
加载数据到内存
修改内存
提交事务
后台写回磁盘
第一种方案,靠谱是靠谱,但频繁 I/O 性能太低,会严重拖累 MySQL 的吞吐量。
第二种方案虽然性能上来了,但如果在第四步时宕机了,而系统认为事务已提交,这时候就会丢失数据了。
那怎么办呢?MySQL 给出的方案是 WAL(Write Ahead Log)机制。WAL 翻译过来就是日志先行的意思。这个日志就是 undo log。具体做法是:
加载数据到内存
修改内存
写入 redo log
提交事务
后台写回磁盘
如果第五步时系统宕机,也可以通过 redo log 来恢复。
你可能有疑问:写入 undo log 不也有磁盘 I/O 吗?这不是脱了裤子放屁,多此一举吗?写 undo log 和写表的区别就在于顺序写和随机写。MySQL 的表数据是随机存储在磁盘中的,而 undo log 是一块固定大小的连续空间。而磁盘顺序写入要比随机写入快几个数量级。
因此,这种方案即保证了数据的安全,性能上也能够接受。
mysql集群部署方式
MySQL Replication(主从复制)
MySQL Replication一主多从的结构
MySQL Fabirc
这是在MySQL Replication的基础上,增加了故障检测与转移,自动数据分片功能。不过依旧是一主多从的结构,MySQL Fabirc只有一个主节点,区别是当该主节点挂了以后,会从从节点中选择一个来当主节点。
MySQL Cluster
mysql集群(MySQL Cluster)也是mysql官方提供的。
MySQL Cluster是多主多从结构的
Zookeeper + proxy
Paxos
paxos算法?
如何防止redis雪崩,穿透,击穿
雪崩
原因:
1. 大量redis缓存失效,导致数据库被打死
2. redis服务器挂了
解决方案:
- 将缓存设置成不同时间点的过期时间(在原有设置过期时间上加一个随机数)
- 实现redis高可用,Redis Cluster 或者 Redis Sentinel(哨兵) 等方案。
- 针对某些极少变化的缓存设置为永不过期
穿透
原因:
缓存穿透表示查询一个一定不存在的数据,由于没有获取到缓存,所以没写入缓存,导致这个不存在的数据每次都需要去数据库查询,失去了缓存的意义。
解决方案:
过滤非法数据,如对于像ID为负数的非法请求直接过滤掉,采用布隆过滤器(Bloom Filter)。
针对在数据库中找不到记录的,我们仍然将该空数据存入缓存中,当然一般会设置一个较短的过期时间(30-60分钟)。
击穿
原因:针对热点key缓存失效
解决方案:
- 让该热门key的缓存永不过期
- 使用互斥锁,通过redis的setnx实现互斥锁。
https://zhuanlan.zhihu.com/p/100706208
redis有几种存储方式
Redis有两种持久化的方式:快照(RDB文件)和追加式文件(AOF文件):
- RDB持久化方式会在一个特定的间隔保存那个时间点的一个数据快照。
- AOF持久化方式则会记录每一个服务器收到的写操作。在服务启动时,这些记录的操作会逐条执行从而重建出原来的数据。写操作命令记录的格式跟Redis协议一致,以追加的方式进行保存。
- Redis的持久化是可以禁用的,就是说你可以让数据的生命周期只存在于服务器的运行时间里。
- 两种方式的持久化是可以同时存在的,但是当Redis重启时,AOF文件会被优先用于重建数据
linux系统零拷贝
- 依赖操作系统底层native api
- 将传统的读写次数由4次降底到3次, 提高了效率
- 上下文切换由4次降到2次
可见确实是消除了从内核空间到用户空间的来回复制,因此“zero-copy”这个词实际上是站在内核的角度来说的,并不是完全不会发生任何拷贝。
在Java NIO包中提供了零拷贝机制对应的API,即FileChannel.transferTo()方法。不过FileChannel类是抽象类,transferTo()也是一个抽象方法,因此还要依赖于具体实现。FileChannel的实现类并不在JDK本身,而位于sun.nio.ch.FileChannelImpl类中,零拷贝的具体实现自然也都是native方法,看官如有兴趣可以自行查找源码来看,这里不再赘述。
将传统方式的发送端逻辑改写一下,大致如下。
SocketAddress socketAddress = new InetSocketAddress(HOST, PORT);
SocketChannel socketChannel = SocketChannel.open();
socketChannel.connect(socketAddress);
File file = new File(FILE_PATH);
FileChannel fileChannel = new FileInputStream(file).getChannel();
fileChannel.transferTo(0, file.length(), socketChannel);
fileChannel.close();
socketChannel.close();
https://cloud.tencent.com/developer/article/1744444
两个不同的网站,如何实现登陆状态同步
其实就是sso原理,oauth2
java8函数式编程用过哪些,举例说明
Function
